Data Management Plan (DMP) Overview
Last updated on 2024-04-01 | Edit this page
Overview
Questions
- What is a Data Management Plan (DMP)?
- When should a researcher make a DMP?
- What information should a DMP contain?
Objectives
- Name the components covered in a DMP
- Articulate the purpose(s) of a DMP
What is Data Management?
Data management is a broad term that encompasses collecting, storing, sorting, organizing and sharing data. We all use some form of data management in our lives: making to-do lists, putting paperwork in labeled file folders, organizing photos by trip name. For researchers, data management is an essential part of the research process that enables them to make sense of the vast amounts of data they collect. Data management practices strive to make data FAIR - Findable, Accessible, Interoperable and Reusable. In other words, good data management makes it easy to find, understand, and reuse a specific piece of information again. It also enhances reproducibility by making it clear what data were used to support which conclusion, and increases security by keeping track of sensitive information.
We often speak of the research data lifecycle when educating researchers about data management:
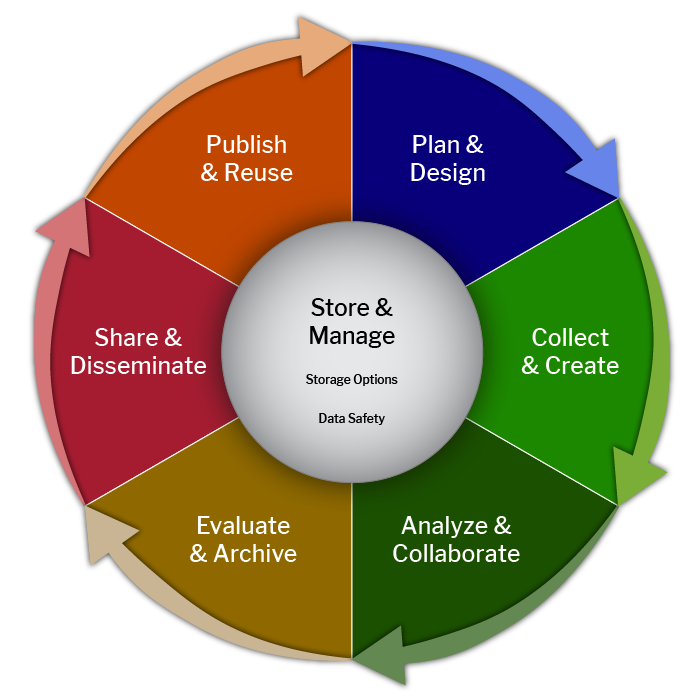
The research data lifecycle represents the stages of data collection, use, and reuse. How data is managed is integral to each step in the cycle. For example, when a researcher collects data, they should use standardized file naming and develop documentation to facilitate its interpretation and analysis. In order to analyze and collaborate, the researcher must organize their data and make it comprehensible to outside parties. In this lesson, we will focus on the data management plan, which should be composed during the “Plan & Design” stage, though it can be updated throughout the lifecycle.
The National Center for Data Services (part of the Network of the National Library for Medicine) defines Data Management Plans in their Data Glossary:
“A Data Management Plan (DMP or DMSP) details how data will be collected, processed, analyzed, described, preserved, and shared during the course of a research project. A data management plan that is associated with a research study must include comprehensive information about the data such as the types of data produced, the metadata standards used, the policies for access and sharing, and the plans for archiving and preserving data so that it is accessible over time. Data management plans ensure that data will be properly documented and available for use by other researchers in the future.*
Data management plans are often required by grant funding agencies, such as the National Science Foundation (NSF) or National Institute of Health (NIH), and are ~2-page documents submitted as part of a grant application process.”
A data management plan, sometimes also called a data management and sharing plan, is generally written by a researcher as part of the planning process before embarking on a project. Spending the time writing a DMP itself can clarify how to carry out data management tasks throughout the entire research data lifecycle. The process also creates a document that can be shared with lab staff or referenced as needed. DMPs are considered a living document and should be updated as circumstances inevitably change through the course of a research project.
Which of the following are uses of a DMP? (select all that apply)
- Component of a grant proposal to inform the agency of your data plans and funding needs.
- Planning how the project will manage its data.
- Creating documentation that can be referenced throughout the research process.
- Listing citations the researcher plans to use in their published paper.
- Component of a grant proposal to inform the agency of your data plans and funding needs.
- Planning how the project will manage its data.
- Creating documentation that can be referenced throughout the research process.
How often should a DMP be updated? (multiple choice, select one)
- Never. Data management plans are created during the funding proposal and need to be followed accurately.
- As needed. DMPs are living documents that are updated as circumstances change throughout the course of a research project.
- Constantly. DMPs should be written as you work on the project, and therefore should be updated every week during the data collection and analysis phases.
- As needed. DMPs are living documents that are updated as circumstances change throughout the course of a research project.
What are the components of a DMP?
The components of a DMP may vary depending on the funding agency. Always check the funding announcement for specific instructions on how your plan should be structured within your proposal and the level of detail required. In general, most DMPs will address the following five elements (each section is followed by an example):
Data Description and Format
The 2013 OSTP Memo defines data as “digital recorded factual material commonly accepted in the scientific community as necessary to validate research findings including data sets used to support scholarly publications, but does not include laboratory notebooks, preliminary analyses, drafts of scientific papers, plans for future research, peer review reports, communications with colleagues, or physical objects, such as laboratory specimens (OMB circular A-110)”. This section of a DMP provides a brief description of what data will be collected as part of the research project and their formats. Information about general files size (MB / GB per file) and estimated total number of files can be helpful. It is not necessary for researchers to describe their experimental process in this section.
Example
From a project examining the link between religion and sexual violence: This study will generate data primarily through (1) participant observations of support groups for those abused by clergy and (2) in-depth, semi-structured interviews with these individuals. Data will be collected via phone calls and video calls hosted on encrypted and passcode-protected conferencing platforms. Data will be collected in the form of audio recordings (MP3, collected on an external recording device free of any network connection), transcriptions of these recordings, physical notes taken during participant observation sessions, and any documents (e.g., email correspondences, scanned copies of letters or photographs) that respondents voluntarily choose to share with the researchers. All data in this study will be de-identified and associated with an anonymizing alpha-numeric code. The research team anticipates that most of these data will be preserved in DOCX, JPG, MP3, PDF, PNG, TXT, or XLSX format. Source (slightly modified)
Metadata and Data Standards
Metadata is information that describes, explains, locates, classifies, contextualizes, or documents an information resource (NNLM). Succinctly, metadata is data about data. A library catalog entry is an example of metadata. Metadata is compiled according to different standards: Dublin Core is an example of a general metadata schema. There are also specific metadata standards for different types of data: for example, MIAME and MINSEQE are commonly used for genomic data. We will discuss data standards further in Episode 2. This section provides information about what standards will be used, giving context to the data generated for easier interpretation and reuse. Often, discipline-specific data repositories will specify a particular metadata standard for their platform.
Example
From a project quantifying the ecological role of sea coral gardens at multiple spatial scales: Field observation data will be stored in flat ASCII files, which can be read easily by different software packages. Field data will include date, time, latitude, longitude, cast number, and depth, as appropriate. Metadata will be prepared in accordance with BCO-DMO conventions (i.e. using the BCO-DMO metadata forms) and will include detailed descriptions of collection and analysis procedures. Source
Preservation and Access Timeline
The data timeline includes information about when data will be backed-up, preserved, and published. Some agencies specify in their policies when the dataset must be shared, such as at the end of the reporting period (the active research phase). In addition to specifying their timelines, this section requires researchers consider what measures they need to take to ensure data security. Raw data may include identifiers such as PII or sensitive information such as location of endangered species that should be protected during collection and processing. Examples of good security practices include using access restrictions such as passwords, encryption, power supply backup, and virus and intruder protections. Active storage location and appropriate software will depend on data sensitivity level. In addition, before sharing any sensitive data with collaborators or depositing into a repository, the dataset should be de-identified or aggregated.
Callout
Although there are many data de-identification methods, it is beyond the scope of this lesson. For more information, please see the further reading resources on the reference page.
Example
From a project screening for protein biomarkers in human samples: Concomitant with publication of the results of the study, participant level data that have been stripped of demographic information will be published as supplementary data and/or made publicly available (with restricted access as laid out below) in the PI’s institutional data repository, which will mint a DOI and continue providing access for at least 10 years, or as long as the repository exists. Raw proteomics data and accompanying metadata will be made publicly available for at least 10 years. Source
Access and Reuse
Access refers to where the data will be made publicly available, and includes a justification why the repository chosen will help with dissemination, preservation, and reuse. In this section, researchers should also consider if their data will need to be embargoed, or if their dataset can only be published in a controlled access repository. Controlled access repositories require some form of verification before data can be accessed, and are commonly used for human subject research data. In addition, this section includes information on who can reuse the data, typically indicated by a license, and if reuse requires a data use (DUA) or data sharing agreement (DSA). In the event that data cannot be shared due to its sensitive nature, the researcher can use this section to specify why the dataset will not be published, including any ethical or legal issues around sharing data.
Example
For a project developing a diagnostic test to acne-causing bacteria: We will maintain a one-year embargo on data to organize and archive it, performing quality assurance checks prior to making in publicly available on one of the data sharing sites. Some species detected may be listed as endangered (Atlantic sturgeon, right whales) and these locations may not be publicly listed until management agencies have been notified and can protect the species involved. Intellectual property rights will reside with the persons identifying the species detected in passive acoustic data using data classification algorithms or by listening to the sounds. Identified species will have sample sound recordings deposited in the Macaulay Library of Natural Sounds (http://macaulaylibrary.org/). Geographic data of tracks of the AWG will be made publicly available as part of the ECU Coastal Atlas (http://www.ecu.edu/renci/Focus/NCCoastalAtlas.html). Acoustic tag Telemetry data detections will be archived in the Atlantic Telemetry Network (ACT http://www.theactnetwork.com/). Fluorometer data (Turner C3) are typically from a data stream taken at 1 to 2 Hz that is combined with CTD data as separate voltage channels into one file. Files will comprise a line of text for every second measurement, so if complexed with CTD data over long periods of time, they may reach GB size. We will submit our data to DataOne (https://www.dataone.org/). Source
Oversight
This section includes information on who is responsible for data oversight, which includes deciding how often or when actions such as backup, converting files to open access versions, depositing the data into a repository, long term preservation, and data destruction will occur. This also includes education for other members of the project team on the DMP and how to follow it. Generally, the PI is ultimately responsible for ensuring proper data management, but researchers may name any lab staff who will be working on data management as part of the oversight team.
Example
From a project examining the effects of placental dysfunction on brain growth in congenital heart disease: Lead PI and the eight co-investigators from the three sites mentioned above who are directly engaged in the research will be responsible for day-to-day oversight of data management activities and data sharing. Lead PI will meet monthly with key study personnel to ensure the timeliness of data entry and review data to ensure the quality of data entry. Lead PI will ensure that the metadata are sufficient and appropriate and that the data management and sharing plan follows the FAIR data principles. Lead PI will report the DMS related activities as outlined in this DMS plan in RPPR and request approval for a revised plan if there is any deviation from the approved DMS plan. At the project conclusion, the final progress report will summarize how the DMS objectives were fulfilled and provide links to the shared dataset(s). Source
Budget
Although most data management plans do not have a dedicated section on costs, data management should be considered when budgeting for a project, especially when writing a grant application. Costs associated with data management may include:
- Staff time for data management: writing documentation, curating data, maintaining data integrity
- Software to process and manage data
- Data storage above what is normally provided by the university
- De-identification services
- Repository deposit and curation fees
Quiz Questions: DMP Sections
Which information is not found within a DMP? (multiple choice, select one)
- File formats of the data
- Software, tools and code used to create this data
- What additional information (metadata) will be provided to allow for understanding the data, and what disciplinary standards it will follow
- The name of the journals where articles using this data will be published
- Schedules for backing up, publishing, and creating open format versions of files, including who is responsible
- Where the data will be published after the granting period and any conditions for reuse
- The name of the journals where articles using this data will be published
What information should be found within the data type section? (select all that apply)
- The general purpose of the project
- What data will be generated by the project
- What is the expected file type of the data
- How much data will be generated by the project
- How much data storage will cost
- Who in the research team will be responsible for collecting the data
- What data will be generated by the project
- What is the expected file type of the data
- How much data will be generated by the project
Match the sample text with the DMP component:
| 1. Data Description and format | a. We will use the Brain Imaging Data Structure (BIDS) for our data |
| 2. Metadata Standards | b. Data will be deposited in the Zenodo generalist data repository |
| 3. Preservation and Access Timeline | c. The PI will oversee implementation of this plan, with assistance from the lab data manager |
| 4. Access and Reuse | d. As required by the NIMH, we will upload our data in 6 months intervals from the beginning of the project. |
| 5. Oversight | e. We expect to collect 200 survey results, which will be stored in .csv format. |
1-e, 2-a, 3-d, 4-b, 5-c
Key Points
- Data management plans should be written during the planning phase of research and revised as needed.
- In general, a DMP should contain sections on data description and format, metadata and data standards, preservation and access timeline, access and reuse, oversight, and budget.